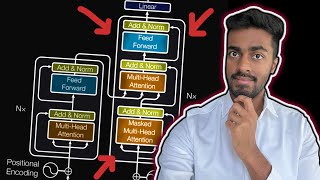
Web Reference: In Lecture 35 of our Gen AI in Hindi series, Bipin Kumar completes the full Transformer Architecture by diving deep into the Decoder — the part that actually generates text in models like... Large-language models (LLMs) have gained tons of popularity lately with the releases of ChatGPT, GPT-4, Bard, and more. All these LLMs are based on the transformer neural network architecture. The transformer architecture was first introduced in the paper "Attention is All You Need" by Google Brain in 2017. LLMs/GPT models use a variant of this arc... Jun 2, 2024 · By the end of this article, you’ll understand how to build, train, and use a decoder-only Transformer model for text generation, with practical examples provided throughout.
YouTube Excerpt: In Lecture 35 of our Gen AI in Hindi series, Bipin Kumar completes the full Transformer Architecture by diving deep into the ...
Information Profile Overview
Lecture 35 Decoder Architecture Explained - Latest Information & Updates 2026 Information & Biography

Details: $62M - $98M
Salary & Income Sources

Career Highlights & Achievements









Assets, Properties & Investments
This section covers known assets, real estate holdings, luxury vehicles, and investment portfolios. Data is compiled from public records, financial disclosures, and verified media reports.
Last Updated: April 3, 2026
Information Outlook & Future Earnings

Disclaimer: Disclaimer: Information provided here is based on publicly available data, media reports, and online sources. Actual details may vary.