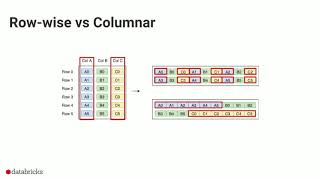
Web Reference: Parquet is a columnar format that is supported by many other data processing systems. Spark SQL provides support for both reading and writing Parquet files that automatically preserves the schema of the original data. When reading Parquet files, all columns are automatically converted to be nullable for compatibility reasons. Parquet is a columnar format that is supported by many other data processing systems. Spark SQL provides support for both reading and writing Parquet files that automatically preserves the schema of the original data. When reading Parquet files, all columns are automatically converted to be nullable for compatibility reasons. The default is gzip. Currently, Spark looks up column data from Parquet files by using the names stored within the data files. This is different than the default Parquet lookup behavior of Impala and Hive. If data files are produced with a different physical layout due to added or reordered columns, Spark still decodes the column data correctly.
YouTube Excerpt: Introduction on
Information Profile Overview
Apache Spark Sql Datasource Parquet - Latest Information & Updates 2026 Information & Biography

Details: $51M - $86M
Salary & Income Sources

Career Highlights & Achievements









Assets, Properties & Investments
This section covers known assets, real estate holdings, luxury vehicles, and investment portfolios. Data is compiled from public records, financial disclosures, and verified media reports.
Last Updated: April 2, 2026
Information Outlook & Future Earnings

Disclaimer: Disclaimer: Information provided here is based on publicly available data, media reports, and online sources. Actual details may vary.